by
匯智軟件 發(fā)布時間:2016/11/8
前置條件:
1、ubuntu10.10安裝成功(個人認為不必要花太多時間在系統(tǒng)安裝上,我們不是為了裝機而裝機的)
2、jdk安裝成功(jdk1.6.0_23for linux版本,圖解安裝過程http://freewxy.iteye.com/blog/882784 )
3、下載hhadoop0.21.0.tar.gz(http://apache.etoak.com//hadoop/core/hadoop-0.21.0/ )
安裝hadoop
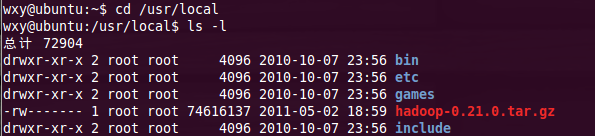
1、首先將hadoop0.21.0.tar.gz復制到usr下的local文件夾內(nèi),(sudo cp hadoop路徑 /usr/local)如圖1
2、進入到local目錄下,解壓hadoop0.21.0.tar.gz,如圖2
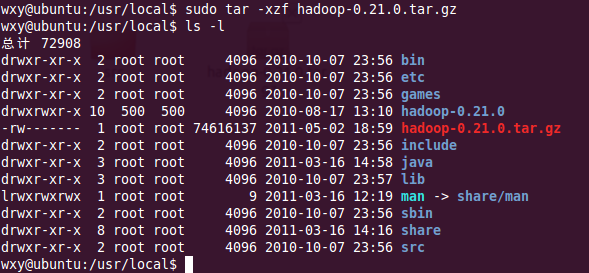
3、為方便管理和hadoop版本升級,將解壓后的文件夾改名為hadoop,如圖3

方便起見,新增hadoop的組和其同名用戶:
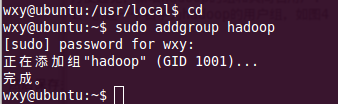
1、創(chuàng)建一個名字為hadoop的用戶組,如圖4
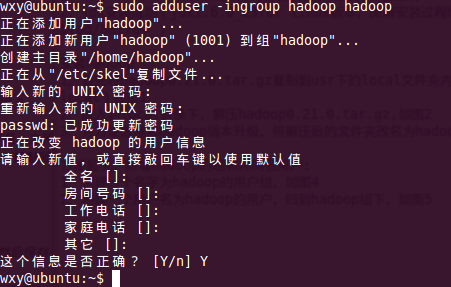
2、創(chuàng)建一個用戶名為hadoop的用戶,歸到hadoop組下,如圖5(一些信息可以不填寫,直接按enter鍵即可)如圖5
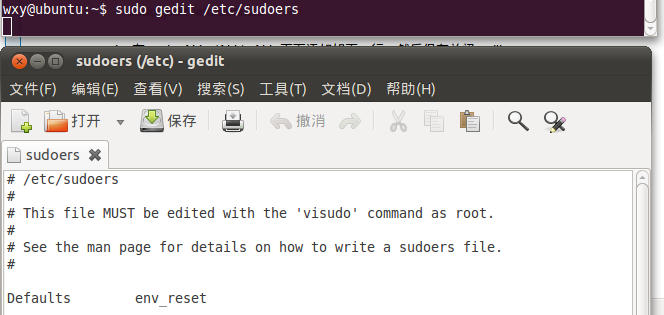
3、(1)添加用戶權(quán)限:打開etc下的sudoers文件,添加如下(2)命令,如圖6
--------------------------------------------------------------------------------------------------------------------------------
(另一種方法是先切換到root用戶下,然后修改sudoers的權(quán)限,但這樣操作一定要小心謹慎,修改權(quán)限后要將文件改回只讀,否則悲劇啦啦啦,我們一票人死在這點上好多次)
(2)在root ALL =(ALL) ALL 下面添加如下文字:
hadoop ALL = (ALL) ALL
如圖7
-----------------------------------------------------------------------------

----------------------------------------------------------------------------------------------
(/etc/sudoers文件是用于sudo命令執(zhí)行時審核執(zhí)行權(quán)限用的)
執(zhí)行命令:$:sudo chown hadoop /usr/local/hadoop(將hadoop文件夾的權(quán)限賦給hadoop用戶)
安裝ssh (需聯(lián)網(wǎng)):(了解ssh:http://freewxy.iteye.com/blog/910820)
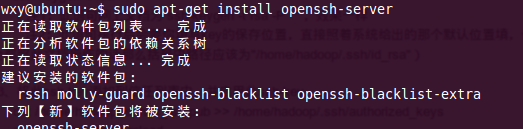
1、安裝openssh_server:如圖8
2、創(chuàng)建ssh-key,為rsa,如圖9
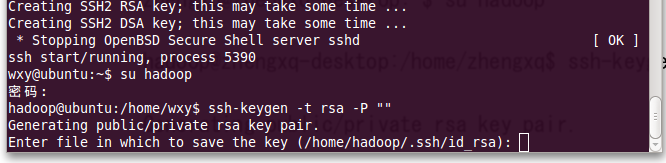
填寫key的保存路徑,如圖10填寫

3、添加ssh-key到受信列表,并啟用此ssh-key,如圖11

4、驗證ssh的配置,如圖12

配置hadoop
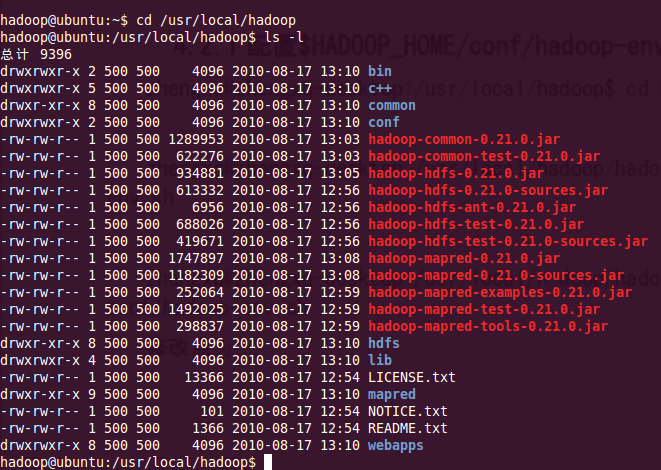
0、瀏覽hadoop文件下都有些什么東西,如圖13
1、打開conf/hadoop-env.sh,如圖14

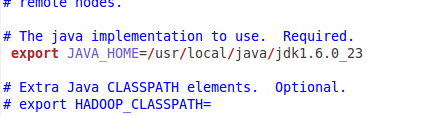
配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本機jdk的路徑),如圖15
---------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------
2、打開conf/core-site.xml
配置,如下內(nèi)容:
Java代碼 
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs:
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3、打開conf目錄下的mapred-site.xml
配置如下內(nèi)容:
Java代碼
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
運行測試 :
1、改變用戶,格式化namenode,如圖18

可能遇到如下錯誤(倒騰這個過程次數(shù)多了),如圖19
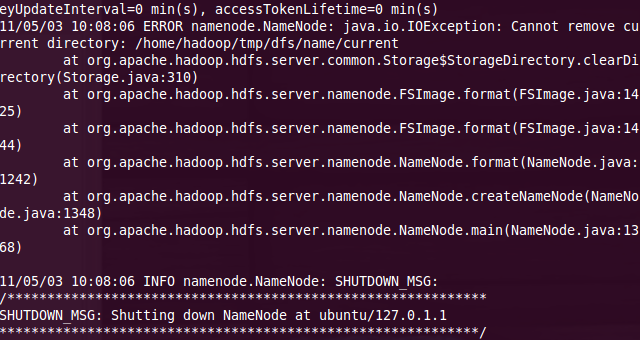
執(zhí)行如圖20,再次執(zhí)行如圖18

2、啟動hadoop,如圖21

3、驗證hadoop是否成功啟動,如圖22

運行自帶wordcount例 子(jidong啊)
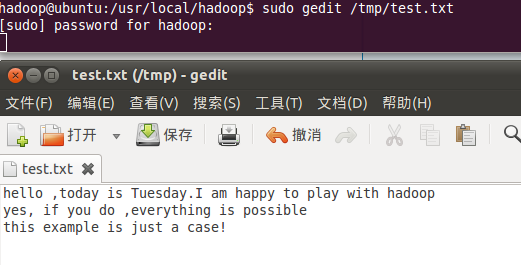
1、準備需要進行wordcount的文件,如圖23(在test.txt中隨便輸入字符串,保存并退出)
-------------------------------------------------------------------------------------------
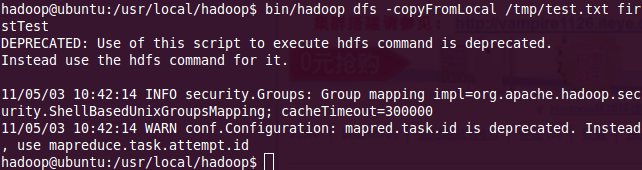
2、將上一步中的測試文件上傳到dfs文件系統(tǒng)中的firstTest目錄下,如圖24(如果dfs下不包含firstTest目錄的話自動創(chuàng)建一個同名目錄,使用命令:bin/hadoop dfs -ls查看dfs文件系統(tǒng)中已有的目錄)
3、執(zhí)行wordcount,如圖25(對firstest下的所有文件執(zhí)行wordcount,將統(tǒng)計結(jié)果輸出到result文件夾中,若result文件夾不存在則自動創(chuàng)建)

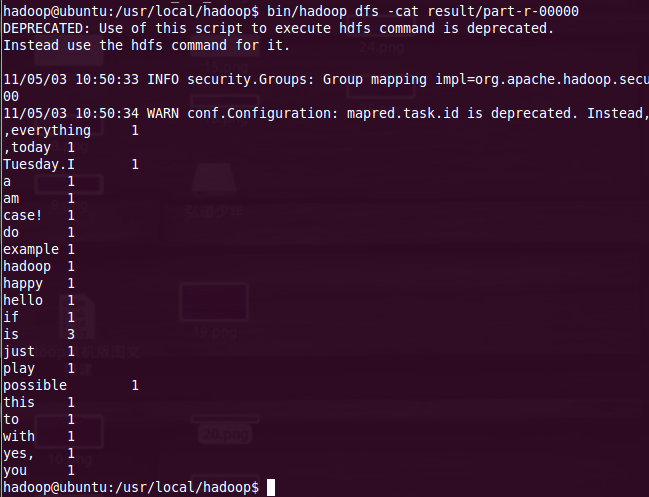
4、查看結(jié)果,如圖26
單機版搞定~~
出處:http://freewxy.iteye.com/blog/1027569 作者:freewxy

